Large language models (LLMs) are machine learning models trained on vast amounts of text data. Their primary function is to predict the probability of a word given the preceding words in a sentence. This ability makes them powerful tools for various tasks, from creative writing, to answering questions about virtually any body of knowledge, and even generating code in various programming languages.
These models are “large” because they have many parameters – often in the billions. This size allows them to capture a broad range of information about language, including syntax, grammar, and some aspects of world knowledge.
The most well-known example of a large language model is GPT-3, developed by OpenAI, which has 175 billion parameters and was trained on hundreds of gigabytes of text. In April 2023, OpenAI released its next-generation LLM, GPT-4, considered the state of the art of the technology today. It is available to the public via ChatGPT, a popular online service.
Other LLMs widely used today are PaLM 2, developed by Google, which powers Google Bard, and Claude, developed by Anthropic. Both Google and Meta are developing their own next-generation LLMs, called Gemini and LLaMA, respectively.
Large language models are part of the broader field of natural language processing (NLP), which seeks to enable computers to understand, generate, and respond to human language in a meaningful and efficient way. As these models continue to improve and evolve, they are pushing the envelope of what artificial intelligence can do and how it impacts our lives and human society in general.
This is part of a series of articles about generative AI.

Let’s review the basic components of LLM architecture:
The embedding layer is the first stage in a large language model. Its job is to convert each word in the input into a high-dimensional vector. These vectors capture the semantic and syntactic properties of the words, allowing words with similar meanings to have similar vectors. This process enables the model to understand the relationships between different words and use this understanding to generate coherent and contextually appropriate responses.
Positional encoding is the process of adding information about the position of each word in the input sequence to the word embeddings. This is necessary because, unlike humans, machines don’t inherently understand the concept of order. By adding positional encoding, we can give the machine a sense of the order in which words appear, enabling it to understand the structure of the input text.
Positional encoding can be done in several ways. One common method is to add a sinusoidal function of different frequencies to the word embeddings. This results in unique positional encodings for each position, and also allows the model to generalize to sequences of different lengths.
Transformers are the core of the LLM architecture. They are responsible for processing the word embeddings, taking into account the positional encodings and the context of each word. Transformers consist of several layers, each containing a self-attention mechanism and a feed-forward neural network.
![]()
Source: ResearchGate
The self-attention mechanism allows the model to weigh the importance of each word in the input sequence when predicting the next word. This is done by calculating a score for each word based on its similarity to the other words in the sequence. The scores are then used to weight the contribution of each word to the prediction.
The feed-forward neural network is responsible for transforming the weighted word embeddings into a new representation that can be used to generate the output text. This transformation is done through a series of linear and non-linear operations, resulting in a representation that captures the complex relationships between words in the input sequence.
The final step in the LLM architecture is text generation. This is where the model takes the processed word embeddings and generates the output text. This is commonly done by applying a softmax function to the output of the transformers, resulting in a probability distribution over the possible output words. The model then selects the word with the highest probability as the output.
Text generation is a challenging process, as it requires the model to accurately capture the complex relationships between words in the input sequence. However, thanks to the transformer architecture and the careful preparation of the word embeddings and positional encodings, LLMs can generate remarkably accurate and lifelike text.
Large language models have a wide range of use cases. Their ability to understand and generate human-like text makes them incredibly versatile tools.
These models can generate human-like text on a variety of topics, making them excellent tools for creating articles, blog posts, and other forms of written content. They can also be used to generate advertising copy or to create persuasive marketing messages.
By training these models on large datasets of source code, they can learn to generate code snippets, suggest fixes for bugs, or even help to design new algorithms. This can greatly speed up the development process and help teams improve code quality and consistency.
These models can be used to power the conversational abilities of chatbots, allowing them to understand and respond to user queries in a natural, human-like way. This can greatly enhance the user experience and make these systems more useful and engaging.
Finally, large language models can be used for a variety of language translation and linguistic tasks. They can be used to translate text from one language to another, to summarize long documents, or to answer questions about a specific text. LLMs are used to power everything from machine translation services to automated customer support systems.
Here are the main types of large language models:
Autoregressive models are a powerful subset of LLMs. They predict future data points based on previous ones in a sequence. This sequential approach allows autoregressive models to generate language that is grammatically correct and contextually relevant. These models are often used in tasks that involve generating text, such as language translation or text summarization, and have proven to be highly effective.
Autoencoding models are designed to reconstruct their input data, making them ideal for tasks like anomaly detection or data compression. In the context of language models, they can learn an efficient representation of a language’s grammar and vocabulary, which can then be used to generate or interpret text.
Encoder-decoder models consist of two parts: an encoder that compresses the input data into a lower-dimensional representation, and a decoder that reconstructs the original data from this compressed representation. This architecture is especially useful in tasks like machine translation, where the input and output sequences may be of different lengths.
Bidirectional models consider both past and future data when making predictions. This two-way approach allows them to understand the context of a word or phrase within a sentence better than their unidirectional counterparts. Bidirectional models have been instrumental in advancing NLP research and have played a crucial role in the development of many LLMs.
Multimodal models can process and interpret multiple types of data – like text, images, and audio – simultaneously. This ability to understand and generate different forms of data makes them incredibly versatile and opens up a wide range of potential applications, from generating image captions to creating interactive AI systems.
Let’s look at specific examples of large language models used in the field.
The Generative Pretrained Transformer (GPT) models, developed by OpenAI, are a series of language prediction models leading the research on LLMs in recent years. GPT-3, released in 2020, has 175 billion machine learning parameters and can generate impressively coherent and contextually relevant text.
In December 2022, OpenAI released GPT-3.5, which uses reinforcement learning from human feedback (RLHF) to generate longer and more meaningful responses. This model was the basis for the first version of ChatGPT, which went viral and captured the public’s imagination about the potential of LLM technology.
In April 2023, GPT-4 was released. This is probably the most powerful LLM ever built, with significant improvements to quality and steerability (the ability to generate specific responses with more nuanced instructions. GPT-4 has a larger context window, can process conversations of up to 32,000 tokens, and has multi-modal capabilities, so it can receive both text and images as inputs.
Google’s PaLM (Pathways and Language Model) is another notable example of LLMs, and is the basis for the Google Bard service, an alternative to ChatGPT.
The original PaLM model was trained on a diverse range of internet text. However, unlike most other large language models, the PaLM model was also trained on structured data, including tables, lists, and other forms of structured data available on the internet. This gives it an edge in understanding and generating text that involves structured data.
Its latest version, PaLM 2, has 540 billion parameters. It achieves improved training efficiency, which is critical for such a large model, by updating the Transformer architecture to allow attention and feed-forward layers to be computed in parallel. PaLM 2 has significantly improved language understanding, language generation, and reasoning capabilities.
Anthropic Claud is another exciting example of a large language model. Developed by Anthropic, a research company co-founded by OpenAI alumni, Claud is designed to generate human-like text that is not only coherent but also emotionally and contextually aware.
Claud’s major innovation is that it offers a huge context window – it can process conversations of up to 100,000 tokens (around 75,000 words). This is the largest context window of any LLM to date, and opens new applications, such as providing entire books or very large documents and performing language tasks based on their entire contents.
Meta’s LLaMA 2 is a free-to-use large language model. With a parameter range from 7B to 70B, it provides a flexible architecture suitable for various applications. LLaMA 2 has been trained on 2 trillion tokens, which enables it to perform highly in reasoning, coding proficiency, and knowledge tests.
Notably, LLaMA 2 has a context length of 4096 tokens, double that of its predecessor, LLaMA 1. This increased context length allows for more accurate understanding and generation of text in longer conversations or documents. For fine-tuning, the model incorporates over 1 million human annotations, enhancing its performance in specialized tasks.
Two notable variants of LLaMA 2 are Llama Chat and Code Llama. Llama Chat has been fine-tuned specifically for conversational applications, utilizing publicly available instruction datasets and a wealth of human annotations. Code Llama is built for code generation tasks and supports a wide array of programming languages such as Python, C++, Java, PHP, Typescript, C#, and Bash.
Tabnine is an AI coding assistant used by over 1 million developers from thousands of companies worldwide, based on GPT architecture. It provides contextual code suggestions that boost productivity, streamlining repetitive coding tasks and producing high-quality, industry-standard code. Unlike using generic tools like ChatGPT, using Tabnine for code generation or analysis does not require you to expose your company’s confidential data or code, does not give access to your code to train another company’s model, and does not risk exposing your private requests or questions to the general public.
Unique enterprise features
Tabnine’s code suggestions are based on Large Language Models that are exclusively trained on credible open-source repositories with permissive licensing. This eliminates the risk of introducing security risks or intellectual property violations in your generated code. With Tabnine Enterprise, developers have the flexibility to run our AI tools on-premises or in a Virtual Private Cloud (VPC), ensuring you retain full control over your data and infrastructure (complying with enterprise data security policies) while leveraging the power of Tabnine to accelerate and simplify software development and maintenance.
Tabine’s advantages for enterprise software development teams:
In summary, Tabnine is an AI code assistant that supports development teams leveraging their unique context and preferences while respecting privacy and ensuring security. Try Tabnine for free today or contact us to learn how we can help accelerate your software development.

GitHub Copilot vs. Amazon CodeWhisperer
Auto-completion tools are the ABC of increased productivity for developers. But what if those tools were even better? What if your code completion guessed what you wanted to write next and offered complete lines of code? That is what AI/ML-assisted coding is bringing to the table. In a few years, you’ll open an IDE without a coding assistant and get the feeling of a missing tool.
Along with Tabnine, the pioneer of AI coding assistants, Microsoft’s Github Copilot and Amazon’s CodeWhisperer are both part of the AI code assistant category for developers. Both tools do similar things, but which is better for you? We’ll cover the key features and differences between the two and help you find the right fit.
What is GitHub Copilot?
Built on top of OpenAI’s Codex model, Github Copilot is a code completion tool that offers generated code snippets based on context. Trained on billions of lines of code from public repositories (notably including code under both restrictive and permissive licenses), Copilot will make an educated guess and suggest complete lines of code as you type.
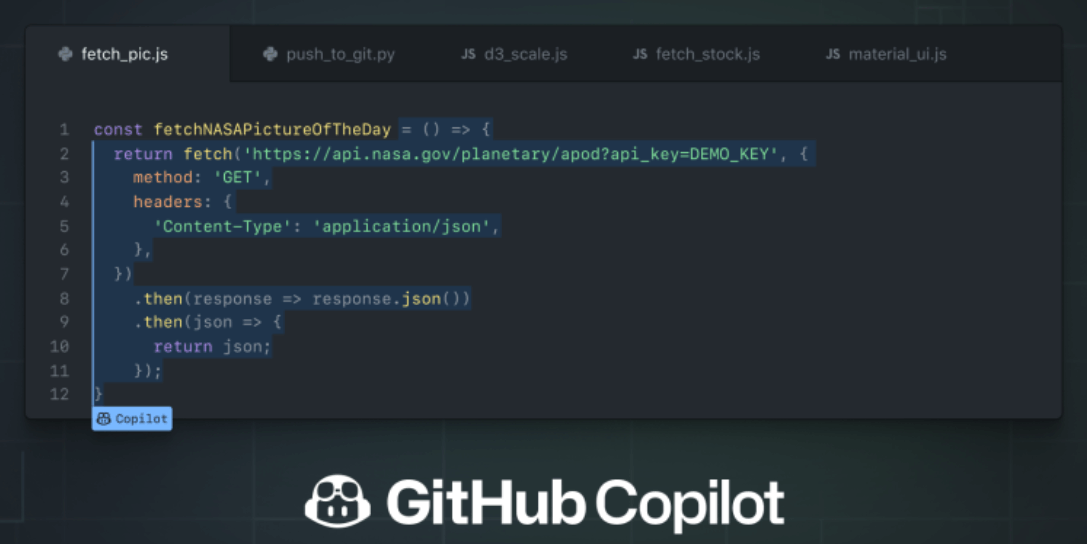
Announced in June 2021 with a limited beta, Copilot supports Python, JavaScript, TypeScript, Ruby, Go, C#, and C++ alongside other programming languages and frameworks.
An important caveat when using Copilot is, “You are responsible for ensuring the security and quality of your code.” When you write code with Copilot, you are the code reviewer, and you must read and understand the code and not blindly trust the AI. It’s also critical to note that, because of how the models were trained, Copilot may recommend code snippets learned from libraries with restrictive licenses. Before using Copilot in commercial software development, engineering teams should check with their legal and compliance teams to ensure they aren’t violating corporate policies.
AI-suggested code – Copilot will suggest code based on project context, style conventions you use, and your cursor’s location.
Multi-language support – Optimized for Python, JavaScript, TypeScript, Ruby, Go, C#, and C++, with more languages to come.
IDE Support – Visual Studio, Neovim, VS Code, and JetBrains.
Control Privacy – You get to choose how Copilot uses the data it collects from you.
Pros:
Cons:
Announced in June 2022 by Amazon, CodeWhisperer aims to help developer productivity using a machine learning (ML) service that generates code recommendations based on contextual information in the IDE, including the code and comments in natural language.
CodeWhisperer supports only Java, Javascript, and Python and supports the JetBrains IDEs, Visual Studio Code, and Amazon’s AWS Cloud9. Like many other tools, CodeWhisperer offers suggestions based on existing code and context, but CodeWhisperer also reads comments.
ML-suggested code – CodeWhisperer will read your comments and suggestions on which code to write to accomplish the task.
Popular IDE support – JetBrains (IntelliJ, PyCharm, and WebStorm), Visual Studio Code, AWS Cloud9, and the AWS Lambda console.
Works best with AWS APIs – CodeWhsiperer is built to work best with AWS APIs, including Amazon Elastic Compute Cloud (EC2), AWS Lambda, and Amazon Simple Storage Service (S3).
Comment Suggestions – CodeWhisperer will make comment suggestions, not only code suggestions.
Pricing:
Unknown at the time of writing.
Pros:
Cons:
Copilot already has a significant hold on the pair programming marketplace, being ahead of CodeWhisperer in the market by a year. It is unclear at this stage if CodeWhiserer has what it takes to establish itself as a significant competitor.
One of the most critical differences between Copilot and CodeWhisperer is the training code used for the AI. While Copilot relies heavily on GitHub public repositories, CodeWhisperer is learning from in-house code and also offers the ability to flag or filter code suggestions that resemble training data to allow developers to check license compliance.
Whether you are choosing an AI coding assistant to make your life easier as an individual developer or choosing a tool to deploy out to your entire engineering team in order to improve the effectiveness and satisfaction of your team, it’s critical to evaluate potential vendors holistically:
Only Tabnine meets all of these requirements expected by enterprise engineering teams and has the history and scale of developer adoption to prove it.
Since launching our first AI coding assistant in 2018, Tabnine has pioneered generative AI for software development. Tabnine helps development teams of every size use AI to accelerate and simplify the software development process without sacrificing privacy & security. Tabnine boosts engineering velocity, code quality, and developer happiness by automating the coding workflow through AI tools customized to your team. With more than one million monthly users, Tabnine typically automates 30-50% of code creation for each developer and has generated more than 1% of the world’s code.
Tabnine provides accurate and personalized code completions for code snippets, whole lines, and full functions. The Tabnine in IDE Chat allows developers to communicate with a chat agent in natural language and get assistance with various coding tasks, such as:
Unlike generic coding assistants, Tabnine is the AI that you control:
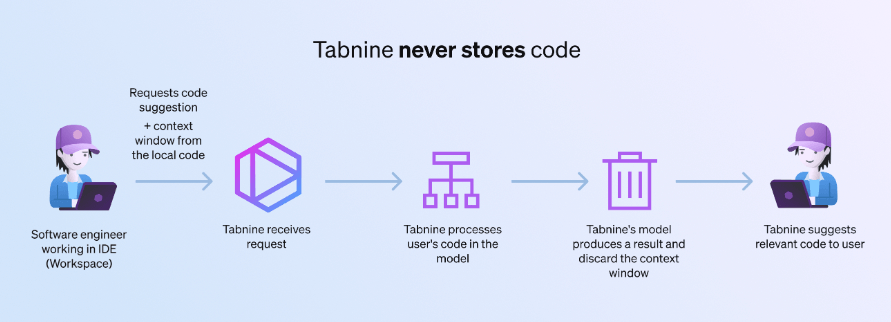
Private
Tabnine ensures the privacy of your code and your engineering team’s activities. Tabnine lives where and how you want it to — deployed as protected SaaS for convenience, on-premises for you to lock down the environment, or on Virtual Private Cloud for the balance of the two. Tabnine guarantees zero data retention, and we never use your code, data, or behaviors to feed our general models.
Personalized
Tabnine is personalized to your team for optimal impact on your business. Tabnine is built on best of breed large language models (with the flexibility to switch as new models emerge or improve), while giving you the ability to fine tune or deploy fully customized models. Tabnine is context-aware of your code and patterns, delivering recommendations based on your internal standards and engineering practices.
Tabnine works the way you want, in the tools you use. Tabnine supports a wide scope of IDEs and languages, improving and adding more all the time. Tabnine also provides engineering managers with visibility into how AI is used in their software development process and the impacts it is having on team performance.
Secured
Tabnine is secure and trusted. Tabnine believes in building trust through Algorithmic transparency, and thus shares how our models are built and trained with our customers. Furthermore, we are relentlessly focused on protecting our customers interests by only training on code with permissive licenses and only returning code recommendations that will not be subject to future questions of ownership and potential litigation. We respect open source code authors and their rights as well as the rights of each and every one of our customers. c
As you should expect from any vendor, Tabnine offers proven, enterprise-grade security and meets key industry standards.
Get started with Tabnine for free today, or contact us to learn how we can help your engineering team be happier and more productive.
There are some small but significant differences between Copilot and CodeWhisperer, such as the fact that Copilot bases its suggestions on context and style while CodeWhsiperer reads your comments.
If you’re using AWS Cloud9, Lambda, or writing in Java, CodeWhisperer would be your first choice. But if you’re looking to code in a different language or IDE, Copilot will answer your call. If you’re operating in the small overlap between the two, I suggest you give Copilot a go first due to its higher popularity and stability over the past year.
You should be aware there are alternatives to Copilot and CodeWhisperer that have been around for a while. Tabnine supports many IDEs, Rich Text Editors, and languages. You can use the AI-trained auto-completion tool on public repositories for free or pay a subscription fee to train the AI on your private repositories to match your style.
The world of software development is rapidly evolving, with the integration of AI being one of the biggest driving forces. To remain competitive and relevant in this constantly changing landscape, it’s essential to stay up-to-date with the latest advancements and trends. By harnessing the power of AI, software engineers can streamline development processes, reduce errors, and improve software quality.

AI is rapidly advancing, and one of the areas where it’s made a substantial impact is code review.
Traditionally, code review is a manual process where fellow programmers examine each other’s code for mistakes, inefficiencies, and improvements. However, this process can be time-consuming and limited due to the complexity and size of modern codebases.
This is where AI code review comes into play. An AI code review uses machine learning and other AI technologies to automate the code review process, making it easier to evaluate and improve code.
AI cannot replace human code review, which is a crucial part of mentoring and collaboration in development teams. But it can provide a basic level of code review for code that otherwise may not be reviewed at all — which in many cases is a majority of the codebase.
AI code review provides the following key benefits:
AI code review uses machine learning models to review, analyze, and enhance software code. These algorithms are trained on vast amounts of code data and knowledge of best coding practices. This learning process enables the AI to identify patterns, detect deviations from good practices, and suggest improvements in the code.
There are two main ways AI code reviews operate:
Code review based on large language models (LLM)
Modern AI assistants leverage LLMs. These are highly complex machine learning models based on the Transformer architecture and trained on huge text datasets. They can understand code and complex instructions and predict the next token or word in code or text. It can generate human-like code and explanations in response to natural language prompts.
Code review based on LLM provides groundbreaking capabilities, including:
By combining traditional rule-based analysis with the nuanced understanding of LLMs, AI code review achieves a comprehensive and deep inspection of codebases, providing developers with actionable and precise feedback.
Automated error detection and fixes
One of the key features of AI code review is its ability to detect errors in the code automatically. It uses advanced algorithms to identify potential bugs, syntax errors, and other issues that could cause problems in the software’s functionality.
An AI code review system also suggests fixes for these issues, providing developers with a clear path to rectify the problem. This can significantly reduce the time it takes to debug and refactor code.
Code quality assessment
AI code review can evaluate the overall quality of the code. It uses many factors to determine this, including code readability, maintainability, complexity, and adherence to coding standards.
By assessing the code’s quality, the AI can provide developers with a holistic view of their work. It helps them understand not just what’s wrong with their code but also what’s right and how they can improve it further.
Code optimization suggestions
Another powerful capability of AI code review is its ability to suggest optimizations to the code. It uses its understanding of good coding practices and its knowledge of the project requirements to identify areas where the code could be made more efficient or effective.
These optimization suggestions could include ways to simplify complex code structures, reduce redundancy, or improve performance. By implementing these suggestions, developers can ensure their code is as optimized as possible, leading to better software performance and user experience.
Compliance and security checks
AI code review can also help ensure the code complies with relevant regulations and is secure against potential threats. It can check for compliance with coding standards and best practices, ensuring the code meets the necessary quality and performance standards.
On the security front, an AI code review system can look for potential vulnerabilities in the code that could be exploited by malicious actors. It provides developers with information on these vulnerabilities and suggests ways to mitigate them, helping to ensure the software is secure.
Chat interface
AI coding assistants based on LLMs can provide a chat interface that allows developers to provide nuanced, natural language instructions for code reviews.
For example, a developer can say, “Check if there is a risk of memory leaks in this code,” and the AI assistant will focus on this specific issue. Developers can also request code reviews of large bodies of code, such as, “Find all uses of log4j in module X and replace it with another library.” Chat interfaces create many new possibilities for automated code review by AI tools.
Tabnine

Tabnine is an AI assistant tool used by over 1 million developers from thousands of companies worldwide. It’s designed for enterprise use cases, avoiding exposure to copyleft licenses, and addressing privacy, security, and compliance risks. It can be locally adapted to your codebase and knowledge base without exposing your code. In addition, Tabnine can be deployed on-premises or in a VPC for maximum privacy and security.
Tabnine provides contextual code review that helps developers produce high-quality, industry-standard code. Tabnine’s code suggestions are based on LLMs that are exclusively trained on credible open source licenses with permissive licensing. Tabnine optimizes entire code lines and functions based on individual developers’ unique codes and preferences while keeping the privacy of all users.

GitHub Copilot

GitHub Copilot is an AI coding partner that reviews code and provides suggestions in real time. Developers can initiate GitHub Copilot’s suggestions either by beginning to code, or by typing a natural language comment saying what they want the code to accomplish.
GitHub Copilot assesses the context of files a developer is working on and any related files and shares its recommendations within the text editor. Its suggestions are powered by an LLM collaboratively operated by GitHub, OpenAI, and Microsoft.
While GitHub Copilot has impressive capabilities, there are several challenges it raises in an enterprise setting. Copilot may sometimes generate insecure or vulnerable code because it’s trained on large datasets, which may include insecure code. In addition, it might provide code that is copyrighted or licensed under nonpermissive licenses, which creates legal exposure for organizations. In addition, since Copilot is a cloud-based service and cannot be deployed on-premises, businesses should consider potential data privacy and confidentiality concerns.
Amazon CodeWhisperer

Amazon CodeWhisperer is an AI coding assistant that provides single-line or full-function code recommendations directly in the IDE. As developers work, CodeWhisperer reviews their code and evaluates English language comments and surrounding code, inferring what code is required to wrap up the task at hand. It can provide multiple suggested code snippets, allowing developers to select the most appropriate one.
CodeWhisperer’s suggestions are powered by LLMs trained on billions of lines of code, including Amazon’s proprietary code and open source code repositories.
CodeWhisperer is a powerful tool, but it has several important limitations for enterprises. Although it does provide some features to verify the security and quality of the code, it could still generate code that does not meet an organization’s quality or security requirements. Additionally, CodeWhisperer requires access to your source code to generate suggestions. Organizations must ensure proper data protection measures and compliance with relevant regulations.
Snyk Code
![]()
Snyk Code is an AI coding assistant that focuses on security code reviews. It incorporates Static Application Security Testing (SAST) during the coding phase of the development process. This allows devs to construct secure software from the get-go, mitigating the need to discover and rectify issues after the code has been compiled. Snyk Code integrates seamlessly with the IDEs and Source Code Management (SCM) platforms where devs construct and scrutinize code, delivering swift, actionable, and relevant results to address issues in real time.
You can utilize Snyk Code in your IDE or SCM (via the auto PR checks feature) to recognize issues as they infiltrate your code. Like other AI coding assistants, it evaluates code as developers type and provides immediate suggestions without requiring compilation.

Source: Snyk
When Snyk Code spots an issue, it provides practical suggestions for remediation, based on code with similar patterns and data flows in other projects. These case-based examples offer a relevant blueprint for addressing the issue, cutting down on the time required for researching and remediating security issues.
AI code review tools, while unquestionably beneficial, do exhibit certain imperfections. Presently, this technology grapples with specific constraints, which we anticipate will be mitigated through future enhancements.
False positives/negatives
While AI code review tools can be extremely helpful, they’re not perfect. One common issue is the occurrence of false positives and negatives. These are instances where the tool incorrectly flags an issue or fails to detect a real problem.
False positives can be particularly frustrating for developers, as they can lead to unnecessary work and confusion. They can also undermine confidence in the tool, leading developers to ignore its suggestions or even stop using it altogether.
Limited context understanding
Another limitation of AI code review tools is their limited understanding of context. While these tools are excellent at detecting syntactical issues or simple logical errors, they struggle with more complex issues that require a deep understanding of the code’s context and purpose.
For example, an AI tool might not understand the business logic behind a piece of code, or it might not be aware of the specific requirements of the project. This can result in the tool overlooking significant issues or suggesting incorrect fixes. These limitations are significantly reduced, but not eliminated, by the introduction of LLMs.
Difficulty with complex code
AI code review tools can also struggle with complex code. These tools are typically trained on a large amount of code data, and they perform best when the code they’re reviewing is similar to the code they were trained on.
However, when faced with complex or unfamiliar code, these tools can struggle. They might fail to understand the code’s structure or purpose, or they might make incorrect assumptions. This can result in inaccurate reviews and feedback.
Dependence on quality training data
Finally, the effectiveness of AI code review tools is heavily dependent on the quality of the training data they are provided with. These tools learn from the code data they are trained on, and if this data is flawed or limited, the tool’s performance will suffer.
This highlights the importance of providing these tools with a diverse and comprehensive set of training data. The data should cover a wide range of coding scenarios and should include both good and bad examples of code.
Most importantly, AI code assistants should be trained on code that is known to be of high quality, secure, and in line with the organization’s requirements. Otherwise, the code and suggestions it provides could be risky or inappropriate.
Incorporating AI into engineering teams
Tabnine is the AI coding assistant that helps development teams of every size use AI to accelerate and simplify the software development process without sacrificing privacy, security, or compliance. Tabnine boosts engineering velocity, code quality, and developer happiness by automating the coding workflow through AI tools customized to your team. Tabnine supports more than one million developers across companies in every industry.
Unlike generic coding assistants, Tabnine is the AI that you control:
It’s private. You choose where and how to deploy Tabnine (SaaS, VPC, or on-premises) to maximize control over your intellectual property. Rest easy knowing that Tabnine never stores or shares your company’s code.
It’s personalized. Tabnine delivers an optimized experience for each development team. It’s context-aware and can be tuned to recommend based on your standards. You can also create a bespoke model trained on your codebases.
It’s protected. Tabnine is built with enterprise-grade security and compliance at its core. It’s trained exclusively on open source code with permissive licenses, ensuring that our customers are never exposed to legal liability. For more information on how Tabnine Enterprise can benefit your organization, contact our enterprise expert.

The landscape of code review is evolving rapidly, with AI-driven tools playing a growing role. AI code review, leveraging the capabilities of LLMs and other AI technologies, promises a future where code assessment is quicker, more efficient, and less biased. These tools provide numerous advantages, from error detection and optimization suggestions to nuanced understandings of context and multi-language support.
However, while they undoubtedly enhance the code review process, AI code review tools are not without their limitations. Challenges like false positives, context understanding, and dependence on quality training data remind us that AI tools should complement, not replace, human expertise. As AI code review continues to develop and improve, it will serve as a robust partner to human developers, facilitating the creation of efficient, high-quality, and secure software.
Advanced AI tools like GitHub Copilot and ChatGPT transform how developers write and understand code. However, there are several essential differences and distinct features that set these tools apart.
This guide compares GitHub Copilot and ChatGPT in depth, explaining their functionalities, use cases, benefits, limitations, and most importantly, concerns and considerations for organizations seeking to leverage these tools.
GitHub Copilot is an AI-powered code completion tool developed by GitHub in collaboration with OpenAI. Launched in 2021, it’s built on top of OpenAI’s Codex, a powerful language model trained on a vast corpus of code and text from the internet. Copilot is a programming assistant designed to help developers write code more efficiently.
By understanding the context and intent of the code being written, Copilot can suggest relevant code snippets, automating parts of the coding process. It supports various programming languages and frameworks, including JavaScript, Python, HTML, CSS, and more.
GitHub Copilot is trained on a vast corpus of code, creating the risk that some of the code it produces might not follow coding best practices or might contain security vulnerabilities. Organizations should exercise caution and carefully review GitHub Copilot code before using it in software projects.
ChatGPT is an advanced AI language model developed by OpenAI, based on the GPT-4 architecture. It’s designed to understand and generate human-like text and code, enabling it to engage in natural language conversations and provide informative responses. It’s able to accept nuanced instructions and produce code in any programming language, with natural language comments and explanations.
Trained on a diverse dataset from the internet, ChatGPT possesses extensive knowledge across various domains up to a cutoff date in 2021. OpenAI has recently added plugins that allow ChatGPT to browse the Internet and access more current data.
While ChatGPT can assist with answering questions, drafting content, and providing suggestions, its output may be inaccurate or biased due to its training data. Users should exercise critical thinking when using ChatGPT and verify any critical information obtained from it.
GitHub Copilot and ChatGPT are both AI-powered tools developed by OpenAI, but they have distinct purposes and features that cater to different user needs:

When comparing GitHub Copilot and ChatGPT for organizational use, several factors come into play:
When considering the integration of AI into your software development, it’s vital to take the following into account:
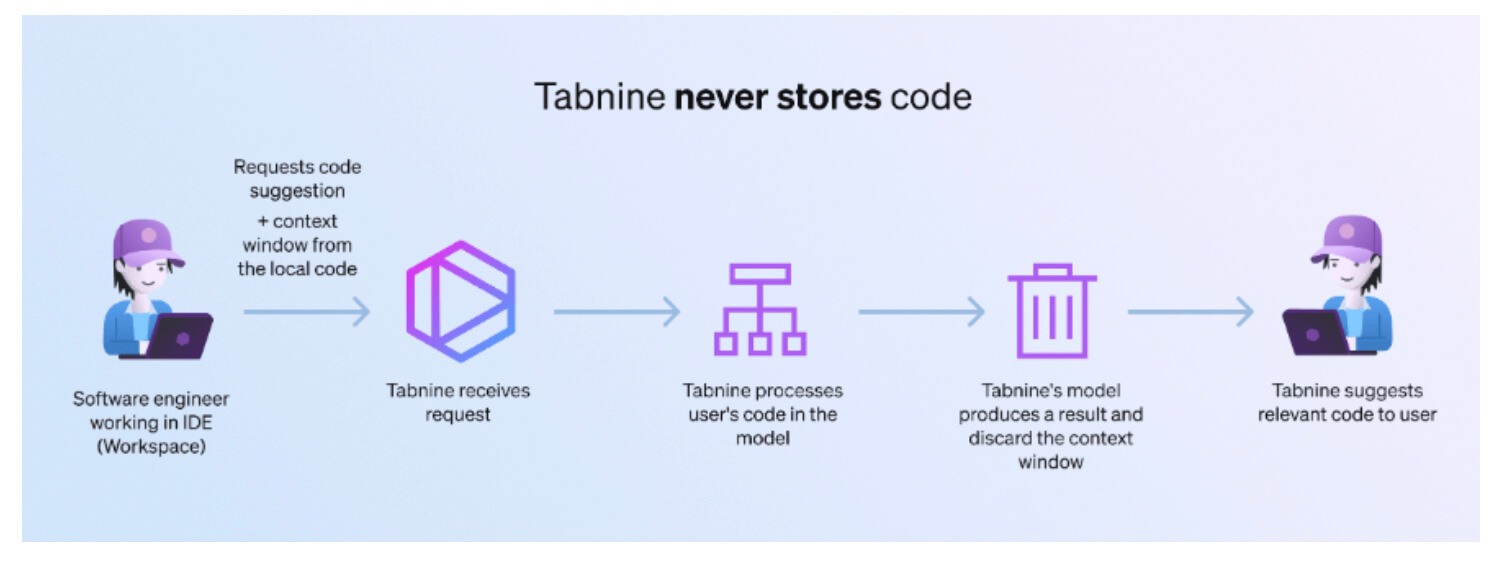
Tabnine is an AI assistant you can trust and that you control, built for your workflow and your environments. Using Tabnine, you get full control over your data, since Tabnine can be deployed in any way you choose: as SaaS, on-premises, or on VPC.
Unlike other AI coding assistants, Tabnine’s models are fully isolated without any third-party connectivity. Tabnine also doesn’t store or share user code. So whether it’s a SaaS, VPC, or on-premises deployment, your code is private and secured.
Tabnine’s generative AI is only trained on open source code with permissive licenses:
Tabnine provides accurate and personalized code completions for code snippets, whole lines, and full functions. The Tabnine in IDE Chat allows developers to communicate with a chat agent in natural language and get assistance with various coding tasks, such as:
Tabnine’s code suggestions are based on large language models that are exclusively trained on credible open source licenses with permissive licensing. Tabnine’s world-class AI models are continually evolving and improving, so they remain at the forefront of technology.
Advantages for enterprises:
Tabnine is built on best-of-breed LLMs (with the flexibility to switch as new models emerge or improve) while offering you the ability to fine-tune or deploy fully customized models. Tabnine is context-aware of your code and patterns, delivering recommendations based on your internal standards and engineering practices.
Tabnine is personalized to your team for optimal impact on your business. Tabnine is built on best of breed large language models (with the flexibility to switch as new models emerge or improve), while giving you the ability to fine tune or deploy fully customized models. Tabnine is context-aware of your code and patterns, delivering recommendations based on your internal standards and engineering practices.
Tabnine supports a wide scope of IDEs and languages, and we’re adding more all the time. Tabnine also provides engineering managers with algorithmic visibility into how AI is used in their software development process and the impact it has on your team’s performance.
Tabnine believes in building trust through algorithmic transparency. That’s why we provide our customers with full visibility into how our models are built and trained. We’re also dedicated to ensuring our customers’ interests are protected by only training on code with permissive licenses and only returning code recommendations that won’t be subject to future questions regarding ownership and potential litigation. At Tabnine, we respect open-source code authors and their rights as well as the rights of every one of our customers.
Get started with Tabnine for free today, or contact us to learn how we can help your engineering team be happier and more productive.
{kind=link}