A few weeks ago I wrote an article that spoke about beginning my journey with Tabnine. At my previous job I had the occasion to play keyboard warrior in the application of machine learning and statistical processes to customer pipelines. But more often than not the job consisted of managing partners and working to ensure top notch delivery to the customer. So it was only moments few and far between where I found myself with the opportunity to code. As I admitted in my previous article I’m an average engineer at best and not having many opportunities to practice certainly did me no favors in improving my capabilities. PEBKAC should probably have been my username. So it was quite apparent to me that Tabnine, and especially Tabnine’s team trained models, would be of great help in getting my efficiency up as an individual contributor. In a few weeks I’ll write an interesting breakdown of some benefits I’ve found in using Tabnine as a dabbler of code, rather than a power user. Hopefully that will be interesting to some of the readers.
But today I’d like to talk about team leads and engineering managers. I won’t do them the grave injustice of assigning them the epithet of “middle management” but that’s kind of where most of these hard working, glue-of-the-orgs find themselves. By and large they don’t code much themselves (or at all as a PM might find) but spend much of their time and energy reviewing PR’s, fixing tech debt, mentoring new hires and working on product roadmaps. None of this work usually has them behind a keyboard for hours writing their own code. So can Tabnine help these valuable folks in their day-to-day, should they care?
Humorously we could perhaps sum up the challenges faced by team leads and managers thusly…
And while we may all laugh and nod knowingly at the preceding tweet, perhaps should ask what are the key motivations for team leaders and managers. According to this paper the top three motivating factors for developers are around improving code quality: finding defects, improving the code, and exploring alternative solutions. Largely, these tasks fall on fellow team members and quite often on the team leads and engineering managers. And while brainstorming code development isn’t something that Tabnine can assist with, reviewing code certainly is. In work by Tufano et. al. titled “Towards Automating Code Review Activities”, they state:
“Our long-term goal is to reduce the cost of code reviewing by (partially) automating this time-consuming process. Indeed, we believe that several code review activities can be automated, such as, catching bugs, improving adherence to the project’s coding style, and refactoring suboptimal design decisions. The final goal is not to replace developers during code reviews but work with them in tandem by automatically solving (or suggesting) code quality issues that developers would manually catch and fix in their final checks. A complete automation, besides likely not being realistic, would also dismiss one of the benefits of code review: the sharing of knowledge among developers.”
And Tabnine believes this is where value can be brought today. By giving the reviewers and mangers the opportunity to automate and improve the mundane aspects of code review and focus instead on the deeper, more complex parts of code improvement. Not only can this improve morale, but there are tangible business reasons to explore this opportunity as well.
Ultimately this points to an increasingly difficult issue facing our industry. The severe dearth of good developers for hire. In an ideal world we would all have access to highly qualified developers at a fair price. AI assisted programming tools might not have the valuable applicability they have today. But finding great devs is like finding hens teeth. Only in fairy tails. Moving forward our industry will have to rely increasingly on tools that enhance the existing skill sets of managers, save valuable time as well as help junior folks become more productive. So consider carefully what tools and methods look like for your organization’s enhancement. I bet that Tabnine will make a good fit!
Are you a project manager or a team lead who always dreams of getting more from your team? This is one of the goals of any software professional who has a product growth mindset.
The famous business quote: “If you can’t measure it you can’t improve it.” ~ Drucker is equally applicable for software development. There are various indicators that can be used to measure the productivity of your software development team. One of these indicators is Software Development Velocity.
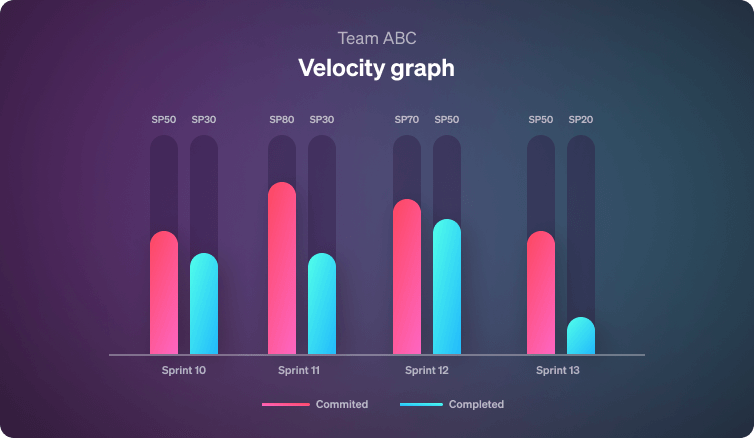
Even if you have already seen velocity graphs in software development, you may not be familiar with Software Development Velocity.
The term “velocity” in software development defines the rate at which a software engineering team delivers work. In simple terms, if the velocity figure is higher, this means that the team does more work within a given period of time.
Specific to a team, Software Development Velocity is an effective metric to predict product delivery. Therefore, it is crucial to get the measuring of the velocity right.
There are two main methods available to measure this:
This Software Development Velocity metric is one of the best indicators of the progress of a software product, which is helpful to predict software release timelines. Suppose a software development team is not analyzing what they committed and what they actually completed for previous sprints. In that case, it makes accurate project planning nearly impossible.
Other than the improved predictability, there are many more advantages of tracking Software Development Velocity. These include gaining a deeper understanding about the team and their performance level, being able to set realistic expectations for stakeholders of the project and detecting infrastructural and process limitations.
Here comes the big question! There are some tried-and-tested ways that successful team leads use to increase their team’s velocity. Let’s look at some of the best ones out there.
The simple formula to boost your team’s productivity is to get high-quality work done in a shorter time. For this, your team should have the right tools.
Modern software development incorporates software that helps improve productivity. Machine learning based tools are at the forefront of boosting productivity not just for developers but for all company functions.
By using AI tools for day-to-day software development work, undoubtedly, team productivity can be increased, which will ultimately boost team velocity.
Tabnine’s AI Assistant is one of the most effective tools for increasing Software Development Velocity. Tabnine provides AI-based code completions for you and your development team that boost productivity, supports almost all languages, and is FREE.
Watch this YouTube video to see TabNine in action.
At a glance, this may sound like a conflicting statement. However, focussing on higher quality outputs has proven to translate into a more significant return on investment, making higher velocity figures in the long run.
Time is an extremely valuable resource when it comes to developing software. Every team lead wants to build software as fast as possible, but rushing projects can cause more harm than good. Not only that, it also leaves your team feeling completely burned out and unmotivated.
Instead, make your meetings productive, improve the efficiency of code reviews and do peer testing systematically to ensure better quality products.
If you have an unhappy team, it doesn’t matter how many processes you implement or how many project management tasks you perform. You will always see a lower velocity figure.
Suppose you are a team leader who is always trying to increase delivery by micromanaging your team. Putting too much pressure on your team can create a negative working environment and potentially even make a higher turn-over rate.
Therefore, it is crucial to focus on the well-being of your team and to give your time and attention to understand your team members’ concerns. Equally important is to ensure that your team has the right educational resources should they wish to expand their skills or specialise in a particular topic. This will make them feel much more empowered and confident at work, and ultimately increase their productivity.
When you take care of your team, they will take care of the product.
Never try to manage your team too much; instead, let each team member take ownership of the areas that they really master. Make them feel that they are part of a bigger cause. Once they realize their own potential and the impact they can have in the company’s success, they will put in their best efforts.
Meanwhile, do not forget to cheer and celebrate the team’s success. Organize team outings, casual chats, and occasional surprise gifts and perks to keep the team engaged. Also, having open discussions regarding career progress and compensation is a great way to motivate the team to continue to do well.
The team’s velocity is highly coupled with the team’s composition. If you have to change your team members frequently, this is probably slowing the velocity down. However, realistically, you can’t guarantee the same team to remain together forever. That is why it is extremely important to have a plan B.
Maintaining a Knowledge Management System (KMS) helps you to pass all the relevant information on to new team members, ensuring that they can keep up-to-date with all practices and systems as soon as possible. In your KMS you can document best practices, specifications, and implementation details of product functionalities and architectural designs. If a team member decides to resign, their product expertise should remain with the team. It should be easily transferable to a newcomer as efficiently as possible with a proper KMS.
You should also resource a replacement as quickly as possible. Finding the right talent is extremely difficult, yet you can mitigate the risk of running low on human resources if you already have a talent pool of software developers that you can reach out to.
The Software Development Velocity metric can be an efficient way for you to analyse how your team works and what can be improved. Now that you have a deeper understanding of this metric, how it is measured and its importance, you can use some of the suggestions presented in this article to increase your team’s productivity and ultimately achieve a higher Software Development Velocity.
Modern software is almost always dependent on external libraries. A software project rarely starts from scratch. Javascript apps are built on top of popular frameworks such as node.js, express, React or Angular. The Apache foundation contributed countless auxiliaries for Java programming. Python is no different in that sense. The first step in a new project for many Python programmers is to grab Flask, boto3 or pandas from PyPi – Not to mention the massive deep learning frameworks.
Still, we observed a strange phenomena. We scanned the source code and project files of 549,007 Python repositories from GitHub. We detected that at least 410,370 of them had import clauses in its source files for modules from a PyPi library. Out of these, 321,482 (78.3%) did not have a dependencies management file, e.g. requirements.txt, in its top folder. Contrarily, out of more than 1M Javascript files, only half of them did not include NPM files. Why is storing dependencies management files in version control more common in Javascript than python by nearly 30%?
We can only speculate what causes this. One thing, however, stands out: In the list of popular external modules from repositories lacking dependencies management, numpy and matplotlib outranks Django and Flask. This leads us to believe that this gap derives from Python’s role as an on-demand number-cruncher.
Python is known – and loved – for its low administrative overhead. To get some results from Python, just fire up the interpreter from your preferred environment, and start hacking away. No initialization steps, no need for a well-structured project folder. Interactive tools, such as IPython and Jupyter, build upon this trait. You can have many ad-hoc sessions and notebooks instead of some redundant mini-project per each.
This loose attitude comes with a cost. Like in many scripting languages, in Python, code execution is decoupled from its dependencies management. You configure the environment, with its installed libraries, per interpreter, and then use whichever interpreter you want to run your code. Unlike Maven and NPM, Python tools, such as pip and conda, do not keep the list of dependencies in a file per project. It is stashed away in the environment directory.
Keeping track of installed libraries can be redundant for short-lived hacks. However, if your code is important enough for putting it under version control, tracking external dependencies is essential. It makes sure that your work will remain functional, even if checked out freshly, by someone else, or by your future self. How can one keep an up-to-date requirements file with minimal fuss?
The key to keeping track of you Python installations is to first write the dependency to a designated file and then have it installed, instead of remembering to do the opposite. We collected several handy tricks for doing so:
Using pip and a requirements.txt file is the most common method for dependencies management in Python. Updating the requirements file manually can be tedious and error-prone. Instead, let’s combine adding a dependency to the file and installing it into a single shell command: echo some-lib >> requirements.txt; pip install -r requirements.txt
In BASH, you can use this function:
REQ_FILE=path/to/requirements.txt
pip_add() {
echo $1 >> $REQ_FILE
pip install -r $REQ_FILE
}
Some IDEs, such as JetBrains PyCharm, support this method natively, so modifying requirements.txt will prompt an option to install the new dependency.
Pip, the ubiquitous Python dependencies manager, is designed to be lightweight and simple. It’s a good design for a baseline tool. However, alternatives do exist. Both Poetry and Pipenv will keep the same basic commands, such as add and install, but will record the installations to a file while doing so. If you want to keep a pip-like workflow while putting your dependencies under version control, consider using one of these alternative managers.
The above tips would work great for a new project, but what can you do if you have an existing code base that you want to commit to version control?
The out-of-the-box option is to use the pip freeze command. It will output all the currently installed packages to a file. Similarly, use conda list if you use Anaconda.
There are, however, two drawbacks for this approach:
pip or conda. If you have a mixture, or external installations, it will not work.piperqs is an intriguing project. It aims at extracting a list of dependencies and versions directly from the source code. It makes use of the PyPi API and Python modules’ __version__ metadata field. Furthermore, it keeps a list of stdlib packages, and a mapping from non-standard module names to their originating projects. Mapping an import clause from source code to a package name is not a trivial task, so the output may not be perfect. Of course, it will also miss modules that are dynamically imported, e.g. using importlib. That said, it can be a real life-saver when dealing with large legacy projects.
Happy hacking!
Bad code makes for a maintenance nightmare down the line. Once committed, bad code becomes technical debt, and technical debt becomes overwhelming when you don’t go back and fix it. Developers spend 33% of their time dealing with technical debt. How can you prevent technical debt from accruing? With effective and comprehensive code reviews. And how can you make code reviews achieve their goals? A code review checklist is a good start.
Code review is a process of vetting code by another programmer. The primary purpose of code review is to maintain high code quality. Reviewing code can expose issues in logic, readability, dependencies and help improve maintainability. Code review is useful in any team and can even be done by a solo developer with the help of a checklist.

The secondary purpose of code review is to enable team members to collaborate and learn from each other. It doesn’t have to be a senior developer reviewing a junior team member for the transfer of knowledge to be fruitful.
The short answer is everyone. There are different approaches to choosing who will review code, and each method has its pros and cons. Usually, you want some healthy mix of everything, although that is not without risk. What does that mean?
Having senior developers review has the advantage of all code passing through experienced reviewers. The downside is that senior developers’ time is more valuable and expensive, and you may prefer they spend their time doing other things. Junior developers reviewing each others’ code is efficient, but you risk missed issues and lower code quality.
When a developer with specialized knowledge reviews code, they are more likely to catch nuances specific to that area of code. If they are also owners of that codebase, it is beneficial that they are made aware of every change as part of the review process. However, the benefit of a reviewer not being familiar with the changed code is that the developer being reviewed must explain their changes in greater detail thus allowing more team members to familiarize themselves with the code.

Like any checklist, a code review checklist contains things you should check before committing or merging code. The purpose of a code review checklist is to ensure nothing is forgotten in the code review process. Developers can use a code review checklist to review their solo work. A reviewer can use a checklist to improve their review process of others’ code.
An effective code review checklist will not be too long, as that would make developers reluctant to use it. A self-review checklist might differ from a reviewer’s checklist and emphasize other parts of the code review process. In an organization or a team, you might want to have a standardized code review checklist to maintain a high code standard and cohesiveness throughout your code base.

Everyone has different needs for code reviews, and the checklist needs to reflect this. You want a checklist that will cover the critical points that most reviewers should cover without becoming bloated. Use the items below to make your checklist, and cross-reference some other checklists you can find online.
Different developers have varied methods of working on code towards a goal. Most developers I’ve worked with like to jump into the grit of things and start messing around until it works. This method of development can generate unreadable and unmanageable code. Once the code works, you should reevaluate it to see if it meets a good standard. It may be prudent to rewrite the code, or it may only need some formatting, in-line documentation and readability changes.
You can put many other items on this list, especially related to comments.
While rapid prototyping encourages developers to write quick and dirty code and worry about performance when necessary, some applications rely on performance to deliver a good user experience. If your application requires good performance, make sure you have several items on your checklist to address it.
There are possible other concerns that are specific to different types of databases. Add items that are specific to the database you’re using.
Security is a serious concern these days, and shifting left security as early as possible can save resources and reduce risk.
Different organizations will have additional security standards, and you’ll need to make your checklist compatible with those standards. Other categories you may want to include in your checklists include UX/UI, Error Handling, Unit Testing, Automation, and Compatibility.

Code reviews should focus on the big picture. The feedback you’re giving another developer needs to be constructive, and it must be manageable. You don’t want to give a developer a hundred small changes they need to make; you want to provide them with very few overview comments to improve the code. Small mistakes in grammar and naming conventions can inflate the number of comments you’re giving and make it harder for the developer to accept the feedback. AI can reduce the number of low-level mistakes, streamline the majority of the readability and naming issues, and give you a cleaner starting point.