State management is hard. Just ask any President, Senator or frontend dev. Dad jokes aside, state management in JavaScript (and React specifically) is a hot topic for discussion. Sure, you can use this.setState and this.state in your code at first. But as soon as your application grows beyond simple functionality, you will have to address the challenges of React application state management.
The best practice is to tackle this predicament sooner rather than later in the development process. The sooner you adopt a state management approach and library for your project, the less code you will be forced to rewrite as the size and complexity of your code-base grow.
Fortunately for you, you are (by far) not the first person wondering what state management approach to implement in their React frontend application. There are quite a few choices out there, with two framework-agnostic external libraries gaining the most popularity over the past few years: Redux and MobX.

While both Redux and MobX aim to solve the same challenges and address the same issues, they are quite dissimilar. Each has its pros and cons, and a radically different approach to state management in React. Before we can compare them, let’s take a short dive into the core principles of each.
Redux defines itself as “a predictable state container for JavaScript apps”. It was created in 2015 by Dan Abramov and Andrew Clark, looking to create a state management for the React framework. In essence, Redux is a combination of Facebook’s Flux architecture and functional programming concepts drawn from the Elm programming language.

The core principles of Redux are:
MobX is a library that aims to make state management simple and scalable by transparently applying functional reactive programming (TFRP). According to the readme, the approach of MobX is thus: “Anything that can be derived from the application state, should be derived. Automatically.” This includes the UI, data serialization, server communication, etc.
In addition, some of the core principles of MobX include:
Our short introduction to MobX and Redux makes it obviously clear that the functionality they offer and the impact on your workflows differ greatly. There is no doubt that the main criteria for choice is personal preference and coding “style”, as well as project needs. That said, there are some criteria where there is an obvious “winner” between Redux and MobX.
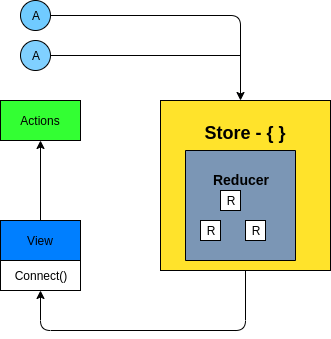
In Redux, there is only one store. It serves as the single source of truth containing normalized data. Redux state is immutable and for each new state, an ancestor state is cloned.
This makes it easier to know exactly where to find the data/state. The downside of this is that the store can quickly turn into an enormous .json file. The upside is in the intuitive nature of this approach. For most developers working on large React projects, having a single source of truth to refer to can be a huge advantage.
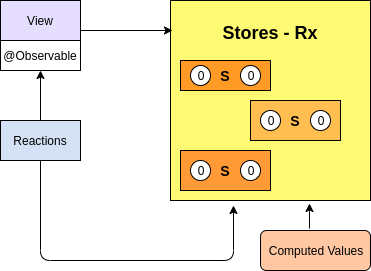
Unlike Redux, MobX usually maintains at least two stores – one for the UI state and one (or more) for the domain state, and they contain denormalized data.
The advantage of multiple stores is in the ability to reuse and query the domain state universally, including other applications. All the while, the UI store would remain specific to the current application.
The disadvantage is clear – multiple stores can quickly lead to clashes and unpredictable results when multiple applications make changes to the domain state.
Redux uses simple JavaScript objects as the data structure to store the state. This requires that updates be tracked manually. Which can add quite a bit of overhead when it comes to applications with complex states to manage and maintain.
MobX uses observable (or noticeable) data to automatically track changes through subscriptions. Quite clearly, automation makes for an easier life for a developer. So it’s no wonder many find MobX to be an obvious winner in this category. It’s simply more comfortable to use.
We’ve already established that Redux uses a single, immutable source of truth for the states stored. This means that states are all read-only, and reducers can overwrite a state invoked by an action. Reducers are pure functions, as they receive a state and action and return a new state.
On the flip side there’s MobX that allows for states to be easily updated and overwritten with new values. While it may be easy to implement, testing and maintaining can become a nightmare of unpredictable outputs.
Perhaps one of the main shortcomings of Redux is the sheer volume of boilerplate code it brings. This is especially true when it comes to React applications.
Since MobX is a lot more implicit in nature, it packs a lot less boilerplate. In this category, MobX is a clear winner.
The purity and somewhat rigid approach of Redux is an advantage when it comes to scalability and debugging of applications. The predictability of pure functions makes Redux much easier to test, maintain and scale than MobX.
As mentioned above, Redux is a lot more predictable than MobX as it comes with a lot less abstraction. Add to that a superior set of developer tools (including time traveling) and you got yourself code that is a breeze to debug.
Unlike Redux, MobX relies a lot more on abstraction, which can produce unpredictable results and generally make debugging difficult. Moreover, the lack of efficient tools for MobX debugging and testing add another hurdle for developers considering MobX for their state management needs.
The path to Redux proficiency is a long one, but those who’ve traversed the steep route claim it’s worth it. This is especially true for developers coming from an object-oriented programming background. Being a combination of Flux and functional programming concepts, Redux is easier to stomach for those with experience in functional programming.
Moreover, employing Redux demands that you learn to work with Redux middleware like Redux Thunk, making the learning curve steeper still.
Since most JavaScript developers are well familiar with object oriented programming, MobX comes naturally to them. With a lot of built-in abstraction, MobX demands a lot less “typing” and results in a lot less boilerplate code. In addition, there is no need to use middleware to implement MobX in your application so learning it is an obviously faster and easier experience.
Comparison articles often consider popularity and a large user community to be critical in choosing a framework or library. Though this is not a popularity contest, there is value to the prevalence of a technology.
More developers using the library means more answers on StackOverflow or Tabnine’s JavaScript Code Library, for that matter. It means better maintained project source code, as well as clearer documentation, and a selection of tools and enhancements.
So which takes the crown in the popularity content? There’s actually no contest as Redux is far ahead of MobX when it comes to community support and prevalence.
Redux has Redux Dev Tools used by thousands of developers debugging Redux code. GitHub stars and contributors? Redux wins. Google Search popularity in 2020? Still Redux. Same is true for npm downloads as well.
As always, there’s no one size fits all and no rule of thumb to guide you in choosing the perfect state management library and approach for your React project.
If you’re looking for a library with the best support, developer community and is built to scale? Redux is probably your answer. However, if you are pressured for time and need to implement state management in a simple proof of concept app? MobX could be the way to go.
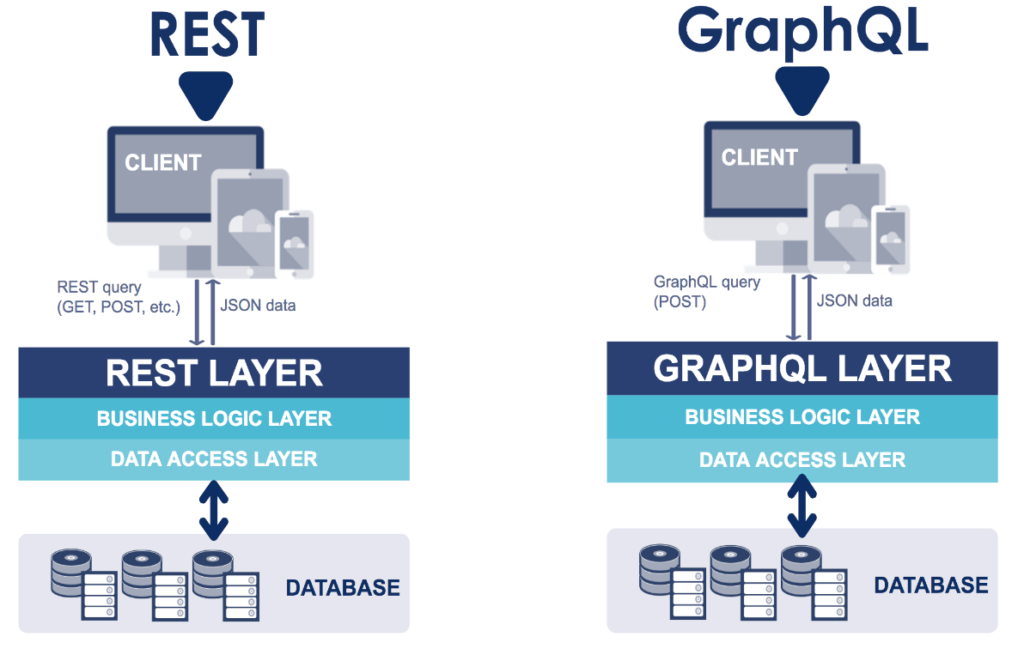
Over the past decade, the web and its data requirements have changed dramatically. When REST APIs came out, SOAP was the predominant methodology for obtaining data from a database. The main thing that allowed REST to take off was its ability to easily communicate data for the frontend to consume.
However, over the years, data requirement complexity has increased. This is increasingly complicated by the different views and user experience requirements for different types of devices and interfaces.
Why is that?
In part, it’s because REST APIs are intricately linked to the frontend views. As frameworks, libraries and platforms come out with new ways to quickly prototype, the backend’s ability to keep up with the speed of changes required is simply not working out with REST.
This is where GraphQL comes in. But what exactly is GraphQL? How does it work? And what’s the difference between REST and GraphQL?
GraphQL has its origins at Facebook. During the time of its development, Coursera and Netflix were also developing something similar. Why is this important? Because it signifies a problem that REST doesn’t address – the need for APIs to be able to adapt to the rapid changes required by the frontend.
While REST is a robust methodology of creating APIs, it’s not elastic in nature. With increased frontend scopes, along with the growing need for iterations and expectations for rapid feature development, an application stack with REST APIs requires time for coding. Why? Because REST requires individual creation of each API.
For example, let’s take a look at a hypothetical set of endpoints requirements for changing an item in the cart.
v1/get/item/{id}
v1/post/removeItem/{id}
v1/post/item/quantity/{quantity}
v1/post/item/setVariation/{id}
v1/post/item/removeVariation/{id}
This is just a quick rundown of what APIs could be made. There’s still the cart management itself, shipping details, promotion codes, special user features, cross sells, upsells and whatever else marketing and UX designers can think up to increase sales.
With REST APIs, you need your backend developers to create an endpoint for all your data requirements. But what if you’re still a bit fuzzy on what you want? What if the business decides to change the requirements midway and come up with a new design? What if the design requires a completely different way of thinking about the data?
All these questions need to be addressed by both frontend and backend developers, resulting in a longer time to production and potentially making work completed a sunk cost to the team.
GraphQL addresses these issues by giving the frontend more power when it comes to data needs.

In a nutshell, GraphQL is a data query language. It lets you interface with a backend implementation that connects up with the database. The backend is still responsible for access controls and deals with how data gets passed between the frontend and the database.
However, GraphQL removes the backend requirement of needing to create specific endpoints for each type of data needed. With GraphpQL, a developer only needs to call a single endpoint and go from there.
This simplifies the process of moving data through APIs and significantly cuts down on the work required every time something new or changes crop up in the specifications.
While GraphQL has been predominantly associated with React, it can be used anywhere and not limited to the library. The association came about due to it being created by Facebook and its initial launched with React.js in 2015 at React.js Conf.
GraphQL allows the frontend to dynamically iterate and design data based on their needs. The frontend developer own needs to send a single request.
While a REST API may be stateless and creates a structured methodology for accessing resources, its major drawback is the high possibility of over or under fetching.
Why is this a problem?
When it comes to mobile-based devices, data size is crucial to the speed of the application. Unlike desktop-based environments where internet connection is generally more stable, mobile network speeds can vary depending on location, service providers, and service areas. The smaller the dataset, the better chances of your user remaining calm and not get frustrated by the slow load time.
Over fetching data results in unnecessary data being transferred. Under fetching can end up with a n + 1 issue – that is, for every additional piece of data required, an additional call API call is needed. So your API calls can result in a tree of calls, which can slow down the responsiveness of your application because of the wait time in between each API.

In contrast, GraphQL lets a developer create dynamic data based on the view’s requirements and only call what’s needed. The query is based on an understanding of how data is structured. In contrast, a REST endpoint will have specific requirements, meaning that documentation is required for every single endpoint.
GraphQL in the backend is implemented based on the schema called Schema Definition Language (SDL). The schema sets the general structure for accessing data. For example, to access the item’s table, a backend developer can set the SDL for GraphQL to something like this:
type Item{
name: String!
quantity: Int!
availability: Boolean!
variations: Boolean!
variationList: Array!
maximumPerCustomer: Int!
unitPrice: Double!
shippingClass: String!
}
All the data above will be accessible by the frontend. However, unlike a REST API, where you’ll end up getting everything, including things may not need for your view, GraphQL lets you create queries and filter a return of data based on what your view needs.
For example, a query for just the name and unitPrice might be required for one view, and only name and shipping class is required for another. Rather than the backend needing to create two REST APIs, the frontend developer can create two queries to the same endpoint.
REST
GraphQL
REST APIs are still relevant and aren’t going to become obsolete when you wake up tomorrow. A majority of the web is still structured in a RESTful manner. However, GraphQL is making headway into the development world as more and more developers adopt it into their application building process.
GraphQL has been around since 2012 but just started to gain traction in the past few years as developers look for ways to increase their output and overall productivity. REST will still be around, but the space of data access and controls is being shared with GraphQL as the query language becomes more mainstream.
More cloud-based providers are also taking up support for GraphQL as part of their product offering. This reduces the overall time required to get an application built by reducing the task of creating a backend to control data access.
I’m super excited to announce that Kyle Simpson, AKA @getify across social media and dev platforms, is today joining forces with Tabnine to expand our Developer Empowerment Program – allowing software developers to leverage AI to code faster and better.
Who is Kyle?
If you do know JavaScript, then you probably already know 🙂
Kyle is one of the most outspoken voices in pushing developers to understand their tools and their craft more deeply. He’s written 10 books with over 200,000 copies sold worldwide, and his online courses have been watched for nearly 700,000 hours. He’s spoken at over 150 events in 24 countries across 6 continents, and he’s taught more than 5,000 developers face-to-face. His passion for broadening and deepening developers’ skills is unmatched.
Sharing a mutual vision – to empower developers
As we began engaging and partnering with leading figures in the dev community, we approached Kyle to ask for some advice, and also to see if he may be interested in collaborating.
We instantly realized that we share a very similar grand vision. Both Tabnine and Kyle are big believers in the open-source web, in building better tools for software developers and in empowering them with the best technology the world has to offer.
Kyle has helped hundreds of thousands of developers learn JavaScript through his books, courses, code, and talks. He’s also worked with dozens of companies to help their R&D teams work better together and is an influencing figure on many topics around evolving technology.
Sharing a mutual vision and an overall philosophy on how AI will empower software developers, both sides felt like we have a very strong basis for an official relationship. The future of the web as we know it is changing rapidly, and we can’t be happier with having Kyle on board, to help us scale up our engagement with the community, sharing our knowledge and insights, and getting feedback from developers who use our products.
As Kyle himself wrote here on his blog post: I admit I became quite intrigued as I discovered their core philosophies are so well aligned with my own: to leverage knowledge and technology to empower people (developers) to achieve more.
What to expect?
As we launch our Developer Empowerment Program, stay tuned for Kyle:
For the JavaScript community in particular, this is a double treat. Not only will @getify continue to preach and teach JavaScript in all its glory, but now he will also spice it up with AI and Machine Learning and see where it all fits in and how it helps you know JS even better.
We can’t wait to see Kyle bring Tabnine and the global community of software developers together, ensuring your feedback helps us empower you and stretch AI beyond its limits.
Welcome Kyle!
Dror Weiss,
Tabnine CEO.
Never assume the usefulness of a tool by its age. After all, they still use hammers in spaceship construction. This is also true for Vim, a text editor with its roots deep in UNIX. Though it was released back in 1991, it maintains an avid community of developers and users. Not only because so many are still trying to figure out how to exit it.

Much like Notepad++ and Sublime, Vim is a text editor rather than full-fledged IDE. This means that almost all functionality is added via plugins. From language-specific syntax checking to handy UI additions and code snippet libraries – there’s something for everyone. At the time of writing, there are 18,959 plugins listed on VimAwesome alone.
While this does indicate that there’s an active community of Vim plugin developers out there, it also creates quite a challenge. How in the world is a dev to pick?
Let us help.
Our list of 15 essential VIM plugins includes the best and most reliable plugins out there that are bound to streamline and improve your work in Vim.
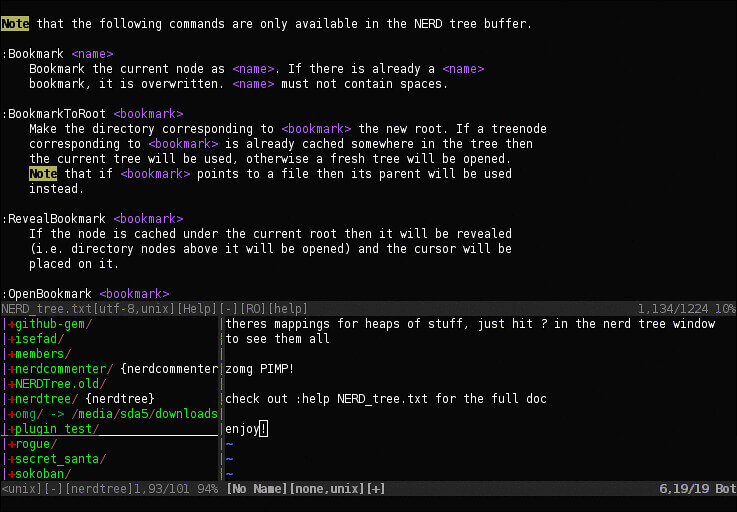
The NERDTree is a file system explorer for the Vim editor. It lets you visually explore complex directory hierarchies in the form of a tree (as the name suggests). With The NERDTree, you can quickly open files for reading or editing and perform basic file system operations using your keyboard and mouse. The plugin can be extended with custom mappings using a special API that you can read more about in the plugins’ documentation.
You will probably forgive us for the shameless plug(in) as soon as you install our Tabnine plugin and use our free multi-language predictive code autocomplete tool. Tabnine Indexes your whole project, reading your .gitignore to determine which files to index. It leverages a mnemonic completion engine to save you from having to type out long file names and paths. With zero configuration needed and high responsiveness (get suggestions in less than 10 milliseconds!), Tabnine is worth trying out.

Tabnine for Enterprise provides a secure coding environment that allows teams and organizations to host and train their own AI models. This feature facilitates collaborative autocompletion across IDEs and enhances code security by keeping the codebase and AI model on secure corporate servers. With Tabnine for Enterprise, your development team can enjoy the benefits of powerful AI code assistance, which promotes more productive and error-free coding, all while ensuring the confidentiality and protection of your company’s data.
[cta_btn url=”https://www.tabnine.com/pricing/landing” label=”Start a free trial”]
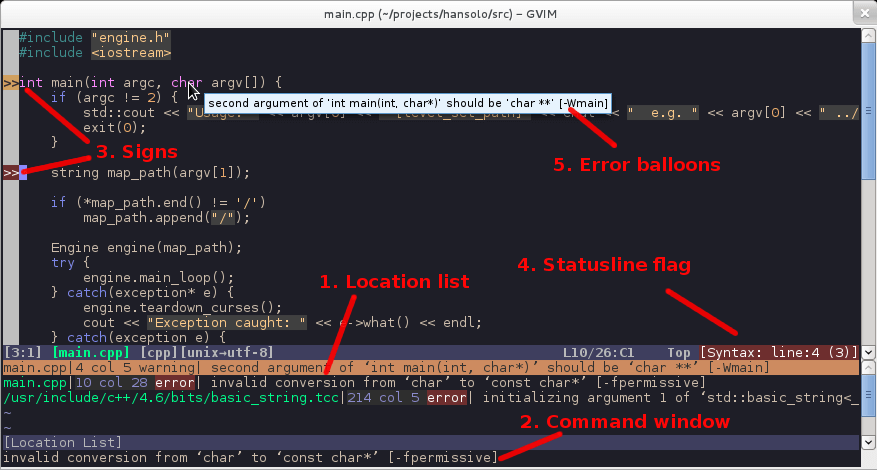
Syntastic is a syntax checking plugin for Vim that runs files through external syntax checkers then displays any resulting errors to the user. This can be done on demand, or automatically as files are saved. Syntastic has checking plugins for most development languages out there, so it’s worth checking out no matter what language (or languages) you code in.
Many developers opt for ack over grep as the search function for enhanced results. For Vim users, this plugin allows searching with ack from within Vim and shows the results in a split window.
ALE (Asynchronous Lint Engine) is a plugin providing linting (syntax checking and semantic errors) in NeoVim 0.2.0+ and Vim 8. It acts as a Vim Language Server Protocol client, and aims to “lint as you type”.
fzf is a general-purpose command-line fuzzy finder, but in itself is not a Vim plugin. The official repository only provides the basic wrapper function for Vim, leaving it up to the users to write their own Vim commands with it. Since this can be a drag, June Gunn created this repository with a bundle of fzf-based commands and mappings extracted from their own .vimrc . These include the “default” implementation of the features users can find in the alternative Vim plugins.
Rainbow brackets / parentheses are not only a colorful addition to your code editor of choice, but a necessary tool to help to discern nested code. This plugin adds Rainbow brackets to Vim while using the default rainbow colors copied from gruvbox color scheme.

There are numerous color schemes out there for Vim. However, Solarized tends to stay popular with users across IDEs and code editing tools. If you’re one of the fans of Solarized, it’s available as a plugin.

Lightline is a light and configurable statusline/tabline plugin for Vim. Forked from the deprecated vim-powerline, lightline is a minimalistic plugin that does not depend on other plugins for functionality. At the same time, it lets users configure and customize it to their needs.
It is very hard to understate the importance of comments in efficient and maintainable code. The NERD Commented plugin defines itself as “a Vim plugin for intensely nerdy commenting powers”. The plugin can digest a great variety of different file types and properly comment each. It can handle single line, multi line, partial line commenting as well as nesting.
This plugin is one of several developed by Tim Pope that have made it into our list. vim-commentary is extremely simple to use: Use gcc to comment out a line (takes a count), gc to comment out the target of a motion (for example, gcap to comment out a paragraph), and gc in visual mode to comment out the selection. That’s it.
The second in our Tim Pope collection is vim-surround. No, it won’t make you able to hear Vim in stereo surround, but will help you manage your parentheses, brackets, quotes, XML tags, and more. The plugin provides mappings to easily delete, change and add such “surroundings” in pairs.
This plugin by Tim Pope shamelessly dubs itself “A Git wrapper so awesome, it should be illegal”. Hence the name – Fugitive. The main feature of Fugitive is :Git (or just :G), which calls any arbitrary Git command. As the documentation states: “If you know how to use Git at the command line, you know how to use :Git.”
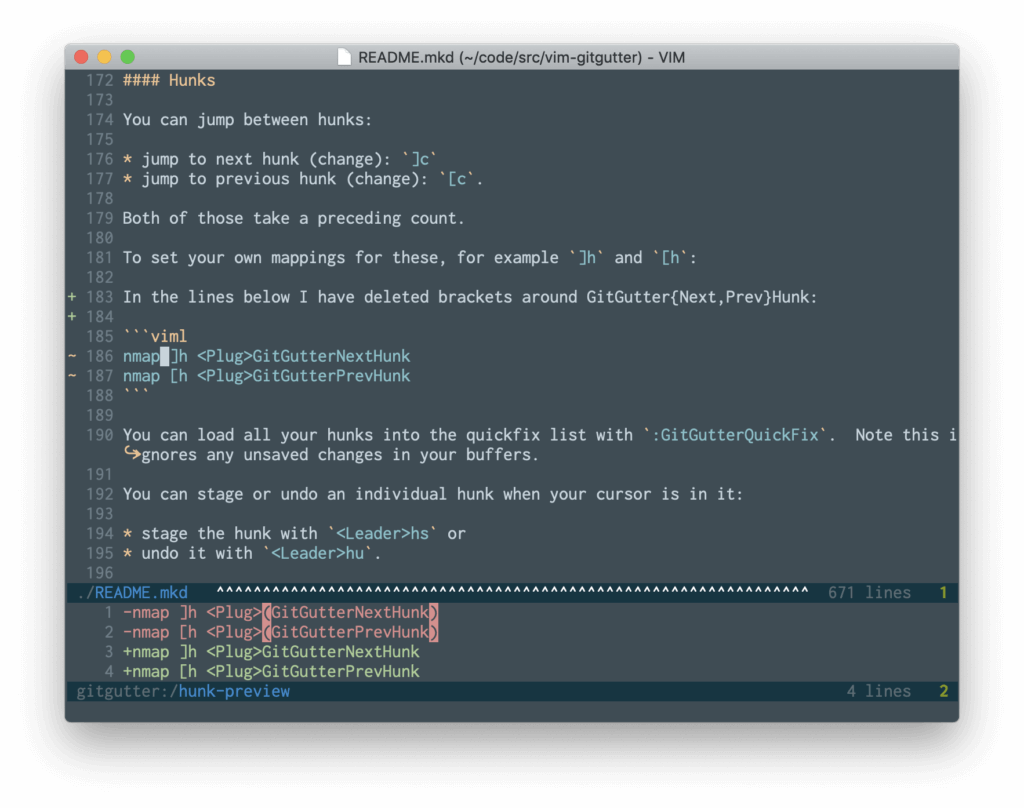
If you’re making use of git repositories in your development process, this well-maintained plugin is a must have. Vim-gutter shows a git diff in the sign column, including which lines have been added, modified, or removed.
That’s a lot of plugins to install and manage! So last but not least on our list is another plugin by June Gunn that will help you keep the rest of your VIM plugins organized – vim-plug. This simple and lightweight plugin manager requires no boilerplate code and also supports externally managed plugins.
It’s worth remembering that while they do add functionality, old and unused plugins are best removed from your code editor of choice, be in VIM or another. Even when they don’t break things or create potential security issues, they still waste precious system resources when they are loaded on startup.